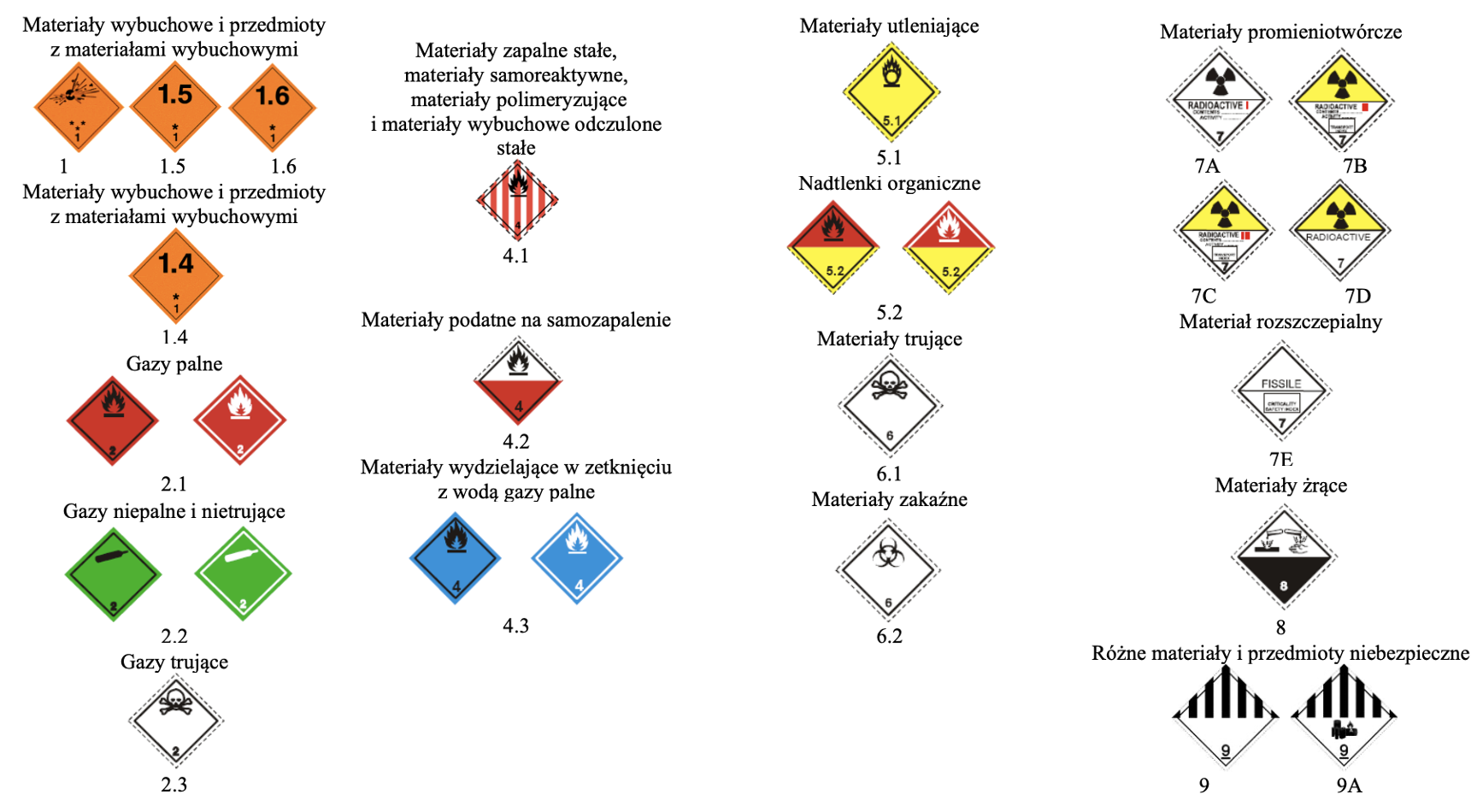
AI w logistyce towarów niebezpiecznych (ADR)
Definicja sztucznej inteligencji w kontekście logistyki towarów niebezpiecznych
W ujęciu powszechnym sztuczna inteligencja (AI) utożsamiana jest najczęściej z kreatywnością i generatywną swobodą. W wysoce zregulowanym środowisku logistyki towarów niebezpiecznych (ADR) definicja ta wymaga jednak fundamentalnego przedefiniowania. Na poziomie strategicznym i operacyjnym przedsiębiorstwa, AI w logistyce ADR to zaawansowany, deterministyczny system wsparcia decyzyjnego, ukierunkowany na zapewnienie rygorystycznej zgodności operacyjnej (compliance) oraz mitygowanie ryzyka prawnego i fizycznego.
Nie jest to narzędzie mające na celu zastąpienie wykwalifikowanego personelu czy doradców DGSA, lecz technologiczny bufor redukujący dług kognitywny pracowników. Jego uniwersalność opiera się na zdolności do natychmiastowej, wielowymiarowej syntezy skomplikowanych i rozproszonych przepisów prawnych, przy jednoczesnym zachowaniu pełnej audytowalności procesu. Z perspektywy zarządczej, lokalnie wdrażane modele AI (działające w architekturze Privacy First) definiuje się jako kapitał intelektualny firmy - zautomatyzowaną warstwę weryfikacyjną, która w czasie rzeczywistym audytuje procesy decyzyjne (np. klasyfikację, dobór opakowań czy wyłączenia), chroniąc organizację przed konsekwencjami błędu ludzkiego, bez narażania wrażliwych danych operacyjnych na ekspozycję w chmurze.
Znaczenie logistyki towarów niebezpiecznych w świetle danych operacyjnych
Logistyka towarów niebezpiecznych to obszar, w którym margines błędu praktycznie nie istnieje, a każda pomyłka operacyjna niesie za sobą ryzyko katastrofalnych skutków dla zdrowia, środowiska oraz stabilności finansowej przedsiębiorstwa. Z perspektywy zarządu, zarządzanie tym łańcuchem dostaw to nieustanne balansowanie między efektywnością a bezwzględnym przestrzeganiem przepisów.
Skalę wyzwań i ukrytego ryzyka operacyjnego doskonale obrazują najnowsze statystyki. Zdarzenia z udziałem towarów niebezpiecznych mają miejsce praktycznie codziennie, nie omijając dni wolnych i weekendów. Analiza danych wskazuje na wyraźną eskalację problemu:
W obiektach produkcyjnych liczba zdarzeń wzrosła z 341 w roku 2024 do 395 w roku 2025;
Analogiczny trend dotyczy obiektów magazynowych, gdzie w 2024 roku zarejestrowano 143 zdarzenia, a rok później zaobserwowano skokowy wzrost liczby pożarów;
Szczególnie niepokojąca i obarczona najwyższym ryzykiem jest tendencja wzrostowa zdarzeń pożarowych związanych z magazynowaniem i produkcją z udziałem towarów niebezpiecznych;
Bezpieczeństwo w samym transporcie drogowym również ulega pogorszeniu - w 2024 roku odnotowano 12 pożarów i 155 innych zdarzeń miejscowych, podczas gdy w 2025 roku liczby te wzrosły odpowiednio do 22 pożarów i 198 innych zdarzeń. Statystyki policyjne potwierdzają tę rosnącą od lat dynamikę.
Za tymi liczbami rzadko kryją się wady maszyn - najsłabszym ogniwem pozostaje czynnik ludzki przytłoczony złożonością procedur. Pogłębione analizy systemowe i audyty państwowych organów kontrolnych obnażają głębokie dysfunkcje organizacyjne w przedsiębiorstwach, które uzasadniają pilną potrzebę cyfrowej transformacji tego sektora:
- Kryzys przygotowania przesyłki - przeważająca większość ujawnianych przez służby naruszeń o krytycznym stopniu ryzyka ma bezpośredni związek z nieprawidłowym przygotowaniem przesyłki już na etapie magazynu lub placu załadunkowego;
- Deficyt procedur kontrolnych - wiele przedsiębiorstw nie posiada wdrożonych (lub skutecznie egzekwowanych) procedur kontrolnych, które weryfikowałyby zgodność operacji z rygorystycznymi wymaganiami Umowy ADR przed wyruszeniem pojazdu w trasę;
- Przeciążenie kognitywne personelu - nienależyte przygotowanie uczestników przewozu do organizowania transportu skutkuje błędami w oznakowaniu, stosowaniu niewłaściwych opakowań czy brakach w obowiązkowym wyposażeniu i dokumentacji. Pracownicy, opierając się na tradycyjnym, manualnym przeszukiwaniu setek stron przepisów, nagminnie popełniają błędy interpretacyjne;
- Niewystarczający nadzór i prewencja: Istniejące modele zarządzania ryzykiem w firmach często mają charakter wyłącznie reaktywny - sprowadzają się do ograniczania negatywnych zjawisk już po fakcie, zamiast opierać się na systemowych działaniach o charakterze prewencyjnym.
Wdrażanie sztucznej inteligencji nie jest zatem poszukiwaniem innowacji dla samej innowacji. Jest to strategiczna odpowiedź na udokumentowane dysfunkcje systemowe. W obliczu rosnącej liczby zdarzeń, AI jawi się jako jedyne skalowalne narzędzie, które potrafi w ułamku sekundy zweryfikować poprawność nakładających się na siebie obostrzeń prawnych, zdejmując z barków personelu ciężar interpretacji wieloznacznych tabel i załączników. Dla zarządów firm logistycznych inwestycja w wyspecjalizowane AI to proaktywna tarcza ochronna - mechanizm, który cyfryzuje compliance, drastycznie zmniejsza ryzyko sankcji finansowych oraz chroni reputację przedsiębiorstwa przed skutkami poważnych awarii.
Wyzwania w implementacji AI w logistyce ADR - problem "halucynacji" i zanieczyszczenia danych
Dostosowanie sztucznej inteligencji do rygorystycznych wymogów transportu towarów niebezpiecznych to wyzwanie wymagające absolutnej, matematycznej precyzji. Największą przeszkodą technologiczną, dyskwalifikującą z profesjonalnego użytku podstawowe, chmurowe modele AI, są tzw. halucynacje. Zjawisko to potęguje fakt, że popularne modele językowe (LLM) trenowane są na gigantycznych, ale niezweryfikowanych zasobach Internetu.
W przestrzeni publicznej nagminnie powielane są błędy pojęciowe - nawet wielu praktyków nie rozumie fundamentalnego rozróżnienia między pojęciem "materiałów niebezpiecznych" a "towarów niebezpiecznych". Sztuczna inteligencja chłonie ten szum informacyjny i traktuje ludzkie pomyłki jako fakty. Ponieważ modele te działają jak zaawansowane silniki statystyczne próbujące za wszelką cenę "wypełnić lukę" w swojej wiedzy, w rezultacie potrafią z ogromną pewnością siebie zmyślać nieistniejące przepisy.
Aby skutecznie zminimalizować to ryzyko, konieczne jest całkowite odcięcie modelu od niezweryfikowanej wiedzy i zakotwiczenie jego procesu decyzyjnego wyłącznie w twardych, zweryfikowanych źródłach prawa - przede wszystkim w obowiązującej Umowie ADR i ustawach krajowych. Z technologicznego i architektonicznego punktu widzenia, wymuszenie na sztucznej inteligencji opierania się na autorytatywnych bazach danych można zrealizować na dwa główne sposoby.
Architektury wdrożenia AI w logistyce towarów niebezpiecznych
Decyzja o implementacji sztucznej inteligencji w strukturach firmy logistycznej wymaga wyboru odpowiedniej architektury technologicznej. Na obecnym etapie rozwoju LLM (Large Language Models), przedsiębiorstwa mają do dyspozycji dwie główne ścieżki: RAG (Retrieval-Augmented Generation) oraz Fine-Tuning (Dostrajanie modelu). Obie realizują nadrzędny cel optymalizacji, jednak różnią się diametralnie pod kątem kosztów, precyzji oraz głębokości zrozumienia procesów operacyjnych.
1. Architektura RAG (Retrieval-Augmented Generation)
RAG można przyrównać do inteligentnego asystenta, który rozwiązuje problemy z otwartą książką (lub w tym przypadku - tysiącstronicowym PDF-em Umowy ADR). Algorytm ten nie posiada "wbudowanej" wiedzy specjalistycznej. W momencie zadania pytania (np. o warunki pakowania dla konkretnego numeru UN), system przeszukuje dostarczoną mu dokumentację, wycina relewantne fragmenty, a następnie na ich podstawie model językowy syntezuje odpowiedź.
Zalety biznesowe:
Szybkość i niski koszt wdrożenia - nie wymaga kosztownego trenowania modelu;
Łatwość aktualizacji - gdy co dwa lata zmieniają się przepisy ADR, wystarczy podmienić plik źródłowy w bazie danych.
Zagrożenia i ograniczenia:
Problem "amnezji" - model zasilany wyłącznie RAG-iem jest całkowicie zależny od dostarczonego dokumentu. Jeśli odłączymy bazę wiedzy lub system wyszukiwania ulegnie awarii, model traci całą swoją eksperckość i staje się bezużyteczny;
Bariera "Chunkingu" (Cięcia tekstu) - Umowa ADR to skomplikowany system naczyń połączonych. Zasada ogólna w jednym rozdziale często warunkowana jest wyjątkiem ukrytym na końcu innej sekcji. Aby dostarczyć tekst do modelu, algorytmy RAG muszą go pociąć na mniejsze fragmenty (tzw. chunks). Jeśli system potnie tekst w złym miejscu, model otrzyma wyrwany z kontekstu urywek i wygeneruje poprawną językowo, ale merytorycznie katastrofalną (i ryzykowną prawnie) odpowiedź;
Ograniczenia "okna kontekstowego" - modele AI mają limit tekstu, który mogą przeanalizować "na raz". Wrzucenie do modelu setek stron zawiłych tabel i przepisów na etapie operacyjnym drastycznie obniża jego precyzję, prowadząc do zjawiska zagubienia w gąszczu informacji.
2. Fine-Tuning (dostrajanie) modelu
Fine-Tuning to proces znacznie głębszy - to "wysłanie modelu na specjalistyczne studia". Zamiast dawać mu książkę do czytania, uczymy go logiki prawno-logistycznej poprzez wgranie bezpośrednio w jego struktury neuronowe dziesiątek tysięcy precyzyjnie przygotowanych par pytań i odpowiedzi (Q&A), kazuistyki i reguł decyzyjnych.
Kluczowe przewagi operacyjne:
Brak "amnezji" i natywna płynność - model po Fine-Tuningu posiada wiedzę wdrukowaną w swoje wagi neuronowe. Nawet bez zewnętrznej bazy dokumentów rozumie, na czym polega wyłączenie 1.1.3.6, czym są ilości ograniczone (LQ) czy jak interpretować numery zagrożenia (HIN);
Głębokie zrozumienie kontekstu - odpowiednio wyuczony model potrafi dedukować. Nie szuka już tylko słów kluczowych, ale analizuje wielowymiarowe problemy (np. weryfikuje zakazy ładowania razem dla kilku różnych substancji jednocześnie), co w architekturze RAG bywa wysoce zawodne;
Niezawodność i szybkość: - z racji tego, że model nie musi na bieżąco przeszukiwać gigantycznych baz PDF, jego odpowiedzi są błyskawiczne i znacznie bardziej zdeterminowane.
Bariera wejścia - głównym wyzwaniem Fine-Tuningu są wyższe koszty początkowe (CAPEX). Proces ten wymaga wynajęcia zaawansowanych klastrów obliczeniowych (GPU) oraz - co najważniejsze - posiadania unikalnego kapitału intelektualnego (Datasetu), wypracowanego przez ekspertów DGSA. Jest to jednak inwestycja o najwyższej stopie zwrotu (ROI) dla firm stawiających na całkowitą niezależność technologiczną.
Privacy First - prywatność w zakresie logistyki ADR ma znaczenie w AI
Niezależnie od wybranej architektury technologicznej (RAG czy Fine-Tuning), warunkiem brzegowym implementacji AI w logistyce musi być paradygmat Privacy First.
Przewoźnicy, operatorzy logistyczni oraz nadawcy na co dzień obracają danymi o krytycznym znaczeniu: listami przewozowymi, składem chemicznym przesyłek, trasami o podwyższonym ryzyku oraz specyfikacjami kontrahentów. Korzystanie z publicznych, chmurowych asystentów AI (jak standardowe wersje ChatGPT) to wystawianie własnego know-how i wrażliwych danych operacyjnych na niekontrolowane przetwarzanie na zewnętrznych serwerach.
Rozwiązaniem tego problemu są Lokalne Modele Językowe (On-Premise / Edge AI). Wykorzystując zaawansowane, otwartoźródłowe modele, cała moc obliczeniowa i proces decyzyjny zamykają się fizycznie na serwerach, a nawet stacjach roboczych wewnątrz firmy. Ani jeden bit informacji, ani jedno zapytanie o ładunek nie opuszcza wewnętrznego intranetu organizacji. Takie podejście nie tylko gwarantuje absolutną suwerenność danych i ochronę tajemnicy przedsiębiorstwa, ale również zapewnia pełną zgodność z normami cyberbezpieczeństwa (w tym wymogami dyrektywy NIS2), chroniąc europejskie łańcuchy dostaw przed infiltracją.
Od teorii do praktyki - budowa dedykowanego modelu ADR i zaproszenie do współpracy
Jak wykazano powyżej, prawdziwą przewagą konkurencyjną w erze sztucznej inteligencji nie jest sam algorytm, lecz specjalistyczna, dziedzinowa wiedza, którą zostanie zasilony. Świadomość tych mechanizmów i technologicznych barier stała się fundamentem naszego autorskiego projektu badawczo-rozwojowego.
Zakończyliśmy budowę unikalnego, wysokiej jakości zbioru danych (datasetu) przeznaczonego do głębokiego dostrajania (fine-tuningu) modeli AI w domenie towarów niebezpiecznych. Obecny zbiór liczy blisko 53 000 ustrukturyzowanych par pytań i odpowiedzi, opartych na polskim tłumaczeniu Umowy ADR oraz przepisach Ustawy o przewozie towarów niebezpiecznych. Baza ta obejmuje kazuistykę prawną, pytania wielokrotnego wyboru, skomplikowane negacje oraz analizy otwartych przypadków operacyjnych.
W najbliższym czasie rozpoczniemy na tych danych proces fine-tuningu wiodących, otwartoźródłowych modeli klasy 7B (w tym m.in. Mistral 7B oraz polskiego modelu Bielik AI). Głównym celem tego eksperymentu jest wypracowanie zdolności sztucznej inteligencji do bezbłędnej, logicznej interpretacji przepisów, precyzyjnego doboru opakowań, analizy zakazów ładowania razem czy trafnej kwalifikacji naruszeń drogowych, przy jednoczesnej eliminacji zjawiska tzw. „amnezji” i halucynacji.
Nawet najlepsza technologia weryfikuje się jednak wyłącznie w zderzeniu z bezlitosnymi realiami biznesowymi i operacyjnymi. Dlatego poszukujemy praktyków ADR - doradców DGSA, inspektorów, logistyków oraz menedżerów łańcucha dostaw - którzy wezmą udział w rygorystycznych testach modelu na realnych zadaniach. Rozwój bezpiecznej sztucznej inteligencji w polskiej logistyce to gra zespołowa. Jeśli chcesz jako jeden z pierwszych w branży sprawdzić, jak lokalne modele AI mogą zoptymalizować procesy compliance i obniżyć ryzyko operacyjne w Twojej firmie - zapraszamy do kontaktu: damian@kocie.mba
Zobacz też:
Artificial Intelligence - what is it?
Analiza transportu towarów niebezpiecznych w państwach członkowskich Unii Europejskiej
Zdarzenia z udziałem towarów niebezpiecznych w okresie 2024-2025