Jak działa nasz kalkulator wyłączeń i wyszukiwarka numerów UN? Od PDF do API
Branża TSL (Transport, Spedycja, Logistyka) od lat opiera się na opasłych tomach umowy ADR. Serce tego dokumentu - Tabela A (Wykaz towarów niebezpiecznych) - to dla wielu logistyków obiekt codziennych zmagań. W erze cyfryzacji manualne przeszukiwanie tabel czy korzystanie z plików PDF jest nieefektywne i podatne na błędy ludzkie. W tym artykule przyjrzymy się bliżej samej Tabeli A, powodom, dla których tak łatwo o pomyłkę, a następnie odsłonimy kulisy powstania ADR apki - aplikacji PWA (Progressive Web App), która przekształca statyczne przepisy w dynamiczny silnik obliczeniowy.
Zrozumieć Tabelę A: anatomia wykazu towarów niebezpiecznych
Tabela A to centralny punkt odniesienia w umowie ADR. Zgodnie z wytycznymi, każdy wiersz tabeli przypisany jest do konkretnego materiału lub przedmiotu pod odpowiednim numerem UN. Brzmi prosto, ale struktura tabeli jest wielowymiarowa i nierzadko skomplikowana.
Wieloznaczność jednego numeru UN
Zasadniczą trudnością jest fakt, że ten sam numer UN nie zawsze oznacza identyczne warunki przewozu. Jak precyzują przepisy: „w przypadku materiałów lub przedmiotów, które objęte są jednym numerem UN, ale mają różne właściwości chemiczne, fizyczne lub odmienne warunki przewozu, może występować kilka następujących po sobie wierszy z tym samym numerem UN”. Oznacza to, że sam numer to za mało - kluczowe jest rozróżnienie na podstawie nazwy, opisu, a często także stanu skupienia czy grupy pakowania.
Nawigacja po kolumnach
Tabela A składa się z kilkunastu kolumn, z których każda niesie ze sobą istotne wytyczne:
- Kolumna (1) i (2): To podstawowa identyfikacja - numer UN oraz prawidłowa nazwa przewozowa. Tu dowiadujemy się, czy mamy do czynienia z konkretnym materiałem, czy pozycją zbiorczą („I.N.O.”);
- Kolumna (3a), (3b) i (4): To kluczowe parametry klasyfikacyjne: numer klasy zagrożenia, kod klasyfikacyjny (określający specyfikę zagrożenia) oraz grupa pakowania (I, II lub III), która definiuje stopień niebezpieczeństwa materiału;
- Kolumny (5) i (6): Wskazują numery wzorów wymaganych nalepek ostrzegawczych oraz odsyłają do przepisów szczególnych (Dział 3.3). Te ostatnie mogą zawierać zwolnienia lub dodatkowe restrykcje, co czyni je niezwykle ważnymi punktami;
- Kolumny (7a) i (7b): Określają zasady przewozu na wyłączeniach - maksymalne ilości dla towarów zapakowanych w Ilościach Ograniczonych (LQ) oraz przypisują kod alfanumeryczny (E0-E5) dla Ilości Wyłączonych (EQ);
- Kolumny (8) do (11): To instrukcje i przepisy szczególne dotyczące pakowania - zarówno w standardowe opakowania i DPPL, jak i cysterny przenośne oraz kontenery do przewozu luzem. Dowiadujemy się stąd np., że kod zaczynający się od „P” oznacza dopuszczenie do przewozu w opakowaniach, a brak takiego kodu - zakaz;
- Kolumny (12) do (14): Skupiają się na przewozie w cysternach ADR - od kodu określającego dopuszczony typ cysterny, przez przepisy szczególne (budowa, wyposażenie, używanie), aż po wymagany typ pojazdu (np. FL, OX, AT);
- Kolumna (15): Zawiera dwie niezwykle istotne informacje operacyjne: Cyfrę (0-4) wskazującą Kategorię Transportową - niezbędną do obliczeń wyłączenia 1.1.3.6 (zasada 1000 punktów) oraz Kod ograniczeń przewozu przez tunele.
Dlaczego w Tabeli A tak łatwo o błąd?
Struktura Tabeli A wymaga od użytkownika nie tylko odnalezienia właściwego wiersza, ale przede wszystkim poprawnego „zdekodowania” informacji rozsianych w wielu kolumnach. Pusta komórka może oznaczać brak przepisów szczególnych, ale również konieczność stosowania wyłącznie rygorystycznych przepisów ogólnych. Co więcej, kody zawarte w tabeli (np. w kolumnie 6, 8 czy 12) to często jedynie odnośniki do innych, obszernych działów umowy ADR. Przeoczenie jednego przypisu lub błędne odczytanie kodu cysterny może skutkować zatrzymaniem transportu lub nałożeniem wysokich kar finansowych.
ADR apka: od PDF do ustrukturyzowanej bazy danych
Wiedząc, z jakimi wyzwaniami wiąże się manualna interpretacja Tabeli A, postanowiliśmy zautomatyzować ten proces. Nasz projekt nie powstał jednak w wyniku prostego "kopiuj-wklej". Źródłem danych jest oficjalna dokumentacja UNECE oraz tłumaczenie Umowy ADR na język polski, opublikowane w Dzienniku Ustaw. Proces cyfryzacji danych przeszedł długą ewolucję:
- Ekstrakcja danych: Pierwszym krokiem było parsowanie oficjalnych plików PDF zawierających Tabele A i B umowy ADR;
- Normalizacja: Surowe dane zostały przeniesione do arkuszy kalkulacyjnych, gdzie nastąpiło ich czyszczenie, typowanie danych i weryfikacja pod kątem błędów odczytu (OCR);
- JSON Transformation: Ostatecznie dane zostały skonwertowane do lekkiego formatu JSON. Dzięki temu aplikacja nie musi ładować ciężkich bibliotek bazodanowych - operuje na zoptymalizowanej strukturze danych, co zapewnia milisekundowe czasy odpowiedzi.
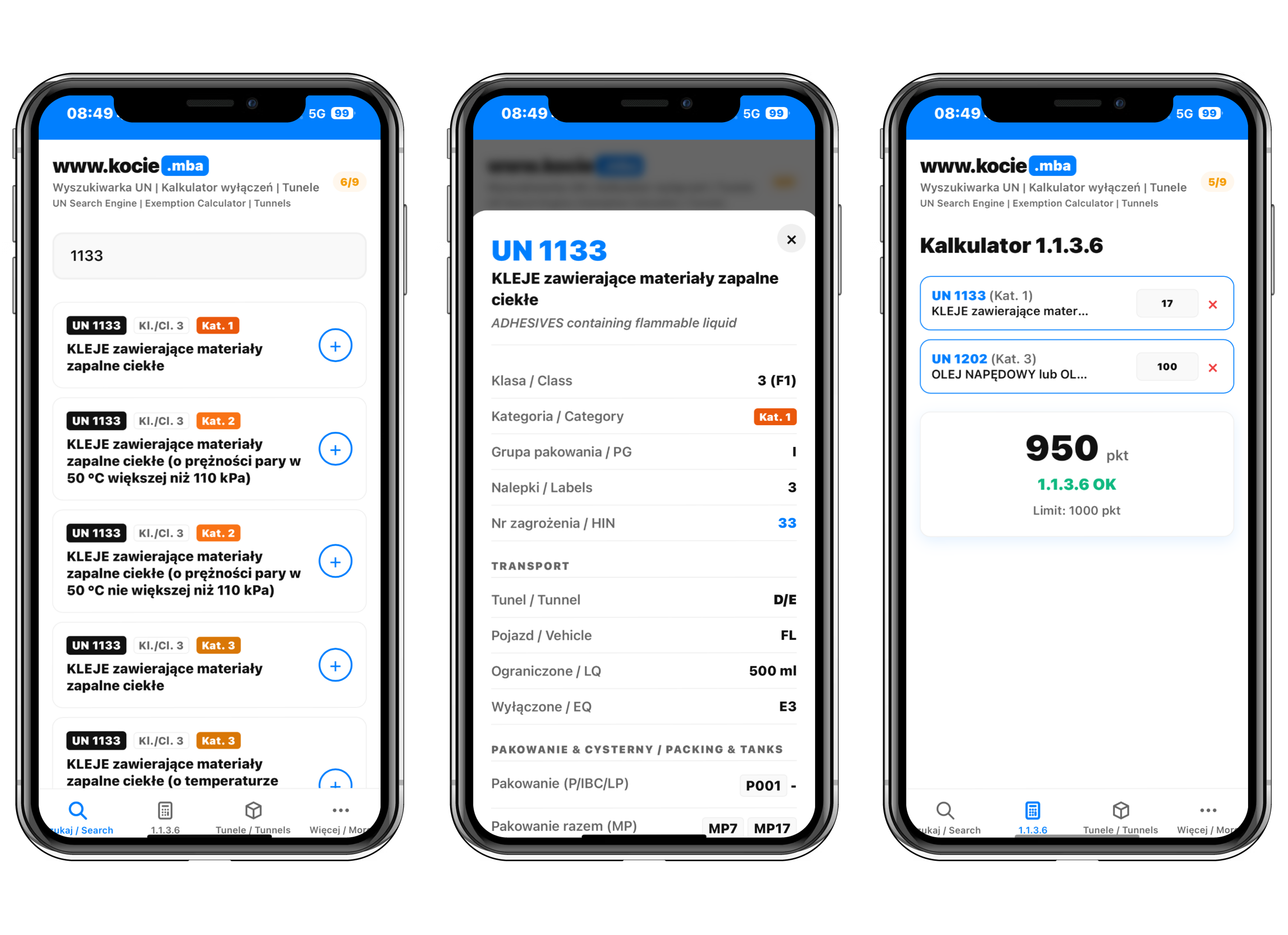
Wyszukiwarka ADR i numerów UN w praktyce
Serce aplikacji stanowi silnik wyszukiwania działający w czasie rzeczywistym. W przeciwieństwie do tradycyjnych rozwiązań, zaimplementowaliśmy logikę "fuzzy search" (wyszukiwania rozmytego). Użytkownik nie musi znać dokładnego brzmienia nazwy chemicznej. Wpisanie fragmentu nazwy (np. "benzyna") lub numeru UN (np. "1202") natychmiast wyzwala zapytanie do API i prezentuje pasujące wyniki, minimalizując ryzyko pomyłki wynikającej z nieprecyzyjnego wyszukiwania.
Kalkulator wyłączeń 1.1.3.6
Największym wyzwaniem inżynieryjnym była implementacja logiki biznesowej ADR, szczególnie w kontekście obliczania wyłączeń 1.1.3.6 (tzw. "małe ADR" lub "zasada 1000 punktów"). Kalkulator działa w modelu dwuetapowym:
- Agregacja: Użytkownik wyszukuje towary i dodaje je do wirtualnego manifestu załadunkowego. Aplikacja przechowuje stan sesji w pamięci lokalnej urządzenia;
- Przetwarzanie: Dla każdej wybranej pozycji system pobiera jej kategorię transportową z bazy danych. Na tej podstawie dobiera odpowiedni mnożnik (x0, x1, x3 lub x50), automatycznie przelicza punkty dla każdego towaru, a następnie sumuje je, podając jasny wynik: status ZIELONY (przewóz dozwolony na wyłączeniu) lub CZERWONY (wymagany pełen reżim ADR).
Dokumentacja API i możliwości integracji (B2B)
ADR apka to nie tylko intuicyjny interfejs graficzny dla doradców i kierowców (dostępny przez aplikację webową). To w pełni funkcjonalne REST API, które udostępniamy dla zewnętrznych systemów. Architektura API opiera się na prostych zapytaniach GET, zwracających odpowiedzi w formacie JSON. Umożliwia to błyskawiczną integrację z systemami klasy TMS (Transport Management Systems), ERP czy aplikacjami magazynowymi (WMS), pozwalając na automatyzację procesów weryfikacji i generowania dokumentacji transportowej.
Zrozumienie i stosowanie Tabeli A wymaga precyzji i doświadczenia. My wierzymy, że oprogramowanie powinno wspierać ekspertów, zdejmując z nich ciężar żmudnych poszukiwań. Jeśli chcesz sprawdzić, jak działa nasze narzędzie, zapraszamy do aplikacji app.kocie.mba. Przedsiębiorstwa zainteresowane wdrożeniem naszego silnika poprzez API zachęcamy do bezpośredniego kontaktu.
Oficjalne źródła, na których oparliśmy naszą aplikację:
Umowa ADR 2025-2027 ogłoszona w Dzienniku Ustaw - Oświadczenie rządowe z dnia 6 marca 2025 r. w sprawie wejścia w życie zmian do załączników A i B do Umowy dotyczącej międzynarodowego przewozu drogowego towarów niebezpiecznych (ADR), sporządzonej w Genewie dnia 30 września 1957 r.
Sprostowanie do Umowy ADR 2025-2027 - Obwieszczenie Ministra Spraw Zagranicznych z dnia 13 listopada 2025 r. o sprostowaniu błędów